Code Generation and YOU
Code Generation and YOU

Introduction
For the past few years I have been thinking about how to build software in ways that scale so that you get 10x the output from the same effort. Recently at work we have gotten indication from management that we’d like to ship faster and their solution has been to increase the speed of hiring, for many reasons this will not work the way they think it will (See The Mythical Man Month by Fred Brooks), but I’d like to present an alternative path that will increase our confidence in our code and decrease our times to ship. In part I’ve been thinking about two series on youtube that explored code generation, why you should use it and what actually works about it, those being “Code Generation (Not the AI Kind)” by Internet of Bugs and Luke Smith’s series on HuGo. I am somewhat disappointed by those explorations of Code Generation since I don’t think either really get to how you can sell an organization with an existing legacy codebase on changing how they develop software or how to graft on code generation to that existing codebase.
I think there are two scenarios in which you should really consider using code generation the first being when you are starting a new project from scratch, this is often the easiest time to leverage the open source code gen tools since you can use frameworks like HuGo for static website generation, Terraform for architecture as code, OpenAPI/Swagger Generation, etc. If you want the most bang for your buck this is the time where picking the right code generation framework can save you a lot of headache down the road and a code gen first approach is one that I prefer for anything other than constrained one off projects. The second and much more common case is when you are coming into an existing codebase that does not use any code gen. Likely you will need to build bespoke tooling to add code gen to a project. Primarily this essay will discuss the latter scenario and why you might want to add code generation tooling to your project besides the obvious benefits of reducing time spent on boilerplate and reducing time spent refactoring generated code. I will also discuss what tools I have found useful in this grafted approach.
Internet of Bugs Code Generation Talk
Luke Smith HuGo Recepies Project
VSCode Codewind tool Open API generation hooks
The Problem with Prioritizing Tooling at the Management Level
“Just because you do not take an interest in politics doesn’t mean politics won’t take an interest in you.” – Various
“You may not be interested in management, but management is interested in you” – rephrase for the age of Kafka’s long nightmare
“Show me the incentive and I’ll show you the outcome” – Charlie Munger
There was a common understanding while I was working at Capital One that the only way for an upper level manager to get to VP was to make an internal tool that was used by a large portion of the company. This top down incentive was broken for a number of reasons but as it pertains to our discussion today, the tooling it creates are not the tools you need but tools that someone else thinks you need and since the tools are put out to the entire company, they are extremely rigid, maybe only changing a few times a year. What I think works is tooling that is flexible. We live in the world of bits where we can transform our companies in an afternoon by pushing the right code. We should treat our tools this way as well, like a hammer that is like clay in the workshop and steel when swung. In order to make tools like this you cannot involve management, they would first of all not see it as a priority (“We are already spending 20% on RnD over here why do I need my code monkeys doing RnD?”) and if they did see it as a priority then they would make the process of tool making too stringent to evolving needs of the codebase, if you need a PR to change how your tools work then you’ve probably made a mistake.
Locality of Behavior, Separation of Concern, Locality of Concern
There is a piece of code generation that I think goes underexplored and is probably way more important than saving you keystrokes or enabling easier refactors of previously generated code. And this is what I call locality of concern. In software there are a few guidelines that many developers use to define good software, the ones I’m thinking about are locality of behavior and separation of concern. Locality of Behavior is the idea that everything that defines the behavior, or the business logic, of a piece of code should be within a few blocks or roughly within a scrollable page of the logic, so if there is a piece of code that modifies how a method behaves it should be close to the method it modifies instead of far away in the same file or in another file. The proposed benefits of following this guideline are that it is easier for the programmer to read and understand the code when looking at it for the first time, and I generally agree with this sentiment.
Putting modifying code in other files or in interfaces where non-obvious interactions occur is what I call information hiding. In general I’ve found code that does “information hiding” is really hard to debug unless I’m the one who wrote it (somehow your own stupid is the easiest to understand). In the extreme the principle of Locality of Behavior states that all information hiding leads to buggy and hard to understand code. Initially the code that does this information hiding might be perfectly sound, but since later programmers likely will not understand that the hidden information exists, they will likely introduce bugs if they are not already present or otherwise waste time trying to understand these hidden side effects.
Okay, sounds good, I will write code that follows this principle of Locality of Behavior and I will convince all of my co-workers to do the same and we will be fine. But what happens when you are hired to work on a codebase that does not follow these principles, you could spend many months or years trying to rewrite code to follow LoB without much support from management, after all spending lots of time on code structure is not the same value as delivering product to customers. Or what happens when the Product team wants Piece A of the code to interact with Peice B in a way that breaks this locality? Almost everything that a system can do that is interesting or valuable involves these cross cutting concerns and as they grow they eat into the legibility and maintainability of your codebase.
The other software ideal I mentioned is separation of concerns. This is the idea that you make clear boundaries between different functional and business portions of your code base. In some ways this separation of concerns is in tension with locality of behavior. As your code base grows it becomes harder to know the true function of any one piece of code. And dividing lines in the code base can hide the true functionality. Think for example on the separation between the different layers of the stack, that being data storage (database), data retrieval (back end) and data display (front end). Ideally we’d like our code to act in concert to manipulate this data as if it were one common object. But too often we find that bugs in the UI have as much effect on whether we store the data correctly as the database does. So in some sense, at least in vertical separation, we have pretended to separate our concerns but different layers of the stack remain tightly coupled.
So what is Locality of Concern then?
This is my idea that tries to marry these two paradigms, keep The different data layers separate and use the LSP server and code generation to rebuild locality of behavior in the abstract.
Why Chick-Fil-A is a Masterclass in Locality, the Founder
There is this movie that came out a few years ago called the Founder that I think illustrates why locality of concern is important. If you haven’t seen the movie it’s about the corporatization of McDonalds under Roy Crock. About half way through the movie there is a scene that has really stuck with me where the McDonalds brothers are training their team on a tennis court in order to figure out how they can arrange their kitchen. They would like to arrange it such that none of their employees will be in each other’s way while cooking and serving meals. The solution they come up with is the equivalent of the Ford assembly line for burgers, each person is responsible for exactly one aspect of the kitchen and their movements are choreographed and timed so that they are never in each other’s way.
If you ever go to Chick-fil-a pay attention to how they do things. All of the specialty drink machines (lemonade, milkshakes, etc.) are right next to each other. They also have an organizing shelf that is a window between and separates the kitchen from the cashiers and has slots for different sizes of chicken nuggets, strips and sandwiches and fries. Notice this means that you basically cannot change the menu (you have to give something up for a good customer experience)! During rush hour they have about four people who all they do is get food from those slots and put them in bags according to customer orders. They have one person whose sole job is to fill up sodas for the drive through lane and make sure the right cars get the right sodas. They have runners outside the building that get the meal bags and sodas together and give them to the right car. They have people outside the building that just take orders and swipe credit cards. They have a separate person outside who checks with the customer that the order was correct and if the restaurant has two drive through lanes checks which lane went first in the queue.
With all of this separation of concerns the Chick-Fil-A by my house regularly processes twice to three times the number of cars as the McDonalds does in the same amount of time. You can also see that they experiment with the layout often (when I was a kid the Chick-Fil-A was very slow at dinner time). All this to say that if Adam Smith designed a restaurant it would be Chick-Fil-A.
One of the other things I’d hope you’d notice visiting a Chick-Fil-A is that the workers there almost never need to move into another person’s section of the restaurant. Everything that they need, except maybe when they need to restock supplies, is within a few feet of their station and everything is duplicated to where the customer might ask for it, so if you need sauce at the cash register the person taking your order just has to reach down to get some, alternatively if you ask for sauce at any point in the drive through, it will be in your bag. Even if you forget to ask earlier than receiving your meal, their drive through window has sauce right there, you just gotta ask.
Why am I talking about Chick-Fil-A in a programming talk? Well, first of all I admire Chick-Fil-A and I think that they are one of the best run businesses in America and I would happily give them all my retirement account to invest if they were a public company. Aside from that, programming is much more like designing a fast food restaurant than most people think. Separation of concern, reuse of processes, and locality of resources make Chick Fil A faster and better than their competitors and they can make us better programmers. I also think the story behind the story I just told you is that Chick-Fil-A owns all of their restaurants outright and over the 10-15 years i’ve been going there have changed dramatically how they do things mostly for the better (wait times have gone down, peak customers have gone up, incorrect order fulfillments down). That level of experimentation and process development over the course of years is something to aspire to.
I also think that the fact that Chick Fil A hires mostly highschool and college students who must be replaced every 2-4 years means that their processes have to be easily understandable by the beginner, since the staff is turning over relatively quickly. In software we often choose obscure design patterns, frameworks and unenforceable coding standards with the idea in our heads that once we teach the whole organization how to follow those patterns frameworks and standards that we will have a team that codes in the way we want and those automatons will produce what our organization has determined is high quality software. This is naive for a few reasons, average tenure at a software company is 2-3 years, In one meeting I was at in a previous company I worked at our company said that our turn over rate on employees was a roughly 18% meaning every five years the entire software department is replaced, I know that specific people will stay longer but I think the point stands that you should expect very little institutional knowledge to stay in whatever company you work at. So what does this mean for developing software?
Clawing back Locality through Code Generation
One of the principal problems I’ve been thinking about is how the tree of code relevant to any change you are trying to make grows with the stack call length of the average endpoint in your system and the number of strands you have to check grows with the number of endpoints in any one service. So as more code is checked into a codebase, the number of relevant code strands and their length will both increase in proportion to the number of features shipped to the server. How can we wrangle this complexity? I think the hammer in me says that this nail should be hit with microservices, but this is often a costly solution and maybe there is a more elegant one that doesn’t require rewriting or breaking apart the codebase.
There are a few options for how to deal with these locality breaking problems, the most enticing is to simply re-write everything from scratch, after writing it the first time you know what the problems with your system are and how you might go about fixing them and what pieces should be close to each other. Often a re-write is necessary or desirable but politically or economically unviable especially on large codebases. One option that I’ve been exploring is to create a map of the codebase that you can operate over using IDE extensions. The idea is that you will never actually be able to maintain Locality of Behavior so instead we should seek to build Locality of Concern at a level above the code base. This Locality of Concern is a virtual amalgamation of the Behaviors in your code base that have been separated from each other due to the size of the codebase, cross cutting concerns, etc. The example I’ve been building at work has to do with getting all of the necessary information for a Springboot-like endpoint together in one JSON and then using that JSON to operate over the codebase using VSCode’s Extension API.
So in a basic Springboot endpoint, you might have one file that has all of your endpoint annotations, many files that have your DTOs and Entities, other files that have your implementation of the endpoint, other files that have the sql and table structure to store that data. You can use the Java Language Server in VSCode to crawl your codebase and coalesce the information about it into a JSON (Reverse Templating) and then write VSCode commands that use this JSON to do operations on the codebase and generate standardized code (Templating).
Once you have this sort of thing set up, it is much easier to refactor your entire codebase since you just need to Reverse Template all of the code in the codebase and then change the Template that you use to generate the code and apply the changes to each file.
An easy example of how this is useful might be adding a field to a DTO. I’m sure we’ve all gotten the ticket a thousand times “Hey we need to add some data to this piece of of the UI that we didn’t plan for here’s a one point to go add that in to the backend”, so instead of going to the database schema modifying that, going to the DTO class and modifying that and going to the typescript object modifying that and then finding everywhere in those three layers where that data is being copied or otherwise modified, you can instead generate a map of that DTO and all of its locations and then re-generate all of the code that the map references with your new field.
I was reading somewhere that tribal groups can learn through cultural education recipies of a certain length in order to make foods local to their area edible. The recipies usually max out at a certian length and are added to over time to make foods less likely to make you sick. They often don’t know why they have to do the steps required and so come up with superstitions around it involving spirits and whatnot in order to preserve the steps in the recipie and usually max out at 12-15 steps. More commonly we know that most people without the use of a counting system can remember numbers up to 5 or 7. You should think about this when deciding wether or not to automate code change tasks in this way: How many “steps” does my current process have and how likely am I to make a mistake at each one?
When to use off the shelf?
Many code generators can already do that operation I just described, so what is the advantage of rolling your own? The problem with using third party generators are the following:
-
They mostly expect you to re-write your codebase to use them exclusively
-
Since you don’t have the structure available to you directly, you cannot write programs using that structure
-
Usually you can only do things that have been accounted for by the team that wrote the generator, since they are likely writing for a general audience this might not line up with what you need
-
Open source generators often are extremly bloated and hard to modify given the above.
Another problem is that they have opinions about how you should use them, for example if we take the OpenAPI generator, I’m sure that it is fine to use on its own, but what if I know that everytime I make a certain generation decision that I also need to modify my AWS infrastructure, OpenAPI has no opinions on that infrastructure and even if it did, what if I use Azure instead, or what if the infrastructure is in a separate repository from my server code? It quickly becomes less and less likely that even if OpenAPI could do all of this generation work for me that they would do it in a way that conforms with what stack I’m using and is integrated into my IDE. I’m not saying that you should never use these tools but when we think about the problems we are asked to solve as software engineers they are rarely ones that cleanly conform to the domains that any one generator could be good at.
The final problem is one of information overload, the great advantage of Open Source is that anyone can contribute to tools that we all use and build upon them, this is also Open Source’s great disadvantage as of writing the openapi-generator github has 5000 issues and 500 pull requests with 52 types of server generators alone. Even if there is a way to solve the problem that comes up in my organization in the way that my organization wants it solved, how would I find that solution and get familiar enough with OpenAPI-Generator’s codebase, so that when I inevitably need to extend something, will I know where and how to do it? And when I move companies or to a new team where they don’t use that specific generator almost all of that specific knowledge is rendered useless.
Often when using these large open source projects we end up pushing the complexity somewhere else rather than reducing it. For these reasons I think it is better to learn the principles of how to do code reverse templating and generation and to keep your tooling light and flexible. Leverage third party generators when you can, but don’t get too stuck into using one for everything. Often these tools are better used in combination with each other than on their own. Remember that for a programmer, the IDE and the tools that they build with it should be an extension of the problems we need to solve in our organization, constantly pruning and adding to this toolbelt is essential.
Three Times to Tool
A good rule of thumb I heard in some tech talk is the idea of three times to tool. The idea is that on the first time you encounter a problem, code it in the most straightforward way possible. On the second time you encounter the problem, do the same but write down a sketch in English of how to solve that problem automatically either using IDE plugins or some other framework for code generation. Finally on the third time you encounter the same problem, write the code for the generation tool and solve the third iteration using your tool while you’re writing the code for the tool.
The nice thing about this approach is you are building the pattern in your mind over weeks or days and so when you actually get to writing the tool you have a good picture of what you need. It also prevents you from automating one off problems or things that don’t generalize. I think another good rule of thumb is start small and build up your code generation skills, the first project I did using HuGo is almost a direct copy of Luke Smiths HuGo project. Very little of the process of using a templating system teaches you how to make a code generation system, but it’ll give you some ideas on what works, what doesn’t and what you could accomplish just by copying from the best. The second project I did in this vein was automatically writing unit tests that were very simple, just put in the filenames that you want to test and feed those filenames into a testing method.
The first IDE extension I made in my free time at the company I’m working at now was a simple copyright documentation updater. We have some policy that copyrights at the top of files must be updated whenever you modify a file to be the current year, so I whipped up some regex to find our copyright, insert it if it doesn’t exist and update it to the current year if it does. Extremely simple, I could have written it in middle school, but the benefit is I saved a bunch of PR comments when I forget to update it and now I have a base knowledge of VSCode Extensions to build off of. The point is you don’t need to build an all encompassing code orchestrator to start, but you’ll likely find the next tool in your list can build off of the previous one and learning more about your plugin system of choice (VSCode, Intellij, NeoVim, etc.) is much easier if you do it in bite sized pieces.
The Prefered Approach
Templating
The first skill you will have to learn is templating, this is very easy and will teach you how to interact with your IDE’s editor system. The basic idea is write a class/file of code and do some string insertion and manipulation to make the class unique to what you are writing. This templating system can exist at runtime or at compile time and likely you will need to decide beforehand what makes sense. For example, in a Travelling Salesman Problem solver I’ve been writing, I put in a command line into the UI that allows for me to run many commands both to turn on/off different flags in the program, run code generation scripts and otherwise interact with the solution that the program came up with.
This runtime approach is powerful since you have the full state of the program available to you when doing code generation, but since you are limited by the metaprogramming techniques that your language provides (e.g in Java this is the reflection package), you may find that the information the language exposes to you is not enough to do the code generation that you wanted and you’ll have little recourse but to go parse your source code.
A good example of this was I wanted my Terminal in my project to be able to automatically list the classes that followed a TerminalCommand interface. This seems simple and any IDE could get you this information for the entire project, but what I ended having to do was get all of the classes in a specific package and check each of those classes to see if it has a super class of the type TerminalCommand anywhere in its linked list of superclasses. That seems fine but if I ever want to move one of the TerminalCommands to another package I’ll have to remember to change where the reflection code is looking for those classes (hidden backlinks are terrible!). In this example it mostly worked out, but there may be things that the reflection package does not expose because they are stripped out at runtime, for example comments/Javadocs. This runtime approach also requires calculations at runtime, many of which will be the same every run. It also requires that you program in a language that supports this kind of mucking around and changing code at runtime, something that most languages do not support and for good reason. But again if you need access to the state of the program in order to write the templates you are thinking of adding, then there is no other option and you’ll have to deal with dangers of self modifying code.
I have found that pairing templating with a LSP server and knowledge of your project’s structure in the IDE at compile time is a very powerful option for generating code that is both debuggable and does not hide information.
Reverse Templating
Reverse templating is the process of parsing an existing, human-written codebase to build a structured, machine-readable model. This model acts as a “map” of your project’s architecture and concerns, which can then be used to drive automated edits and code generation. Instead of starting with data and generating code, you start with code and generate a data model of its structure. This approach is essential for grafting code generation onto a legacy project.
First you need to trace the connections for a given feature to every file that it touches. So for a Spring Boot endpoint you would want to be able to describe the Resource, all of its annotations (is it a GET, PUT, POST? what path does it exist at?), the DTO it returns (what is that DTO’s structure? use the Language server to recursively find the correct symbols to figure this out) and what body does it accept (again describe its DTO).
By the end of this process you should have in a JSON all of the structural information that you’d need to recreate the endpoint fully, but without any of the accompanying code.
You then bind this operation to a command or VSCode action that writes this JSON to a temporary file.
Now that we have the temporary JSON file with all of the infromation that describes our endpoint, we can essentially do anything we want with it. One option that has saved me a lot of time is that you make edits to this JSON and push those changes back out to the code base using Templates that match our JSON structure. This allows us to think at a higher level without getting bogged down in the details of the codebase (questions like: where was that supporting file again? tend to eat up a lot of development time).
Some other quick tools I’ve written were things like:
-
Transform this DTO into a curl for use in postman and add it to my postman library. Some auto-docs already support this, but now it is with the rest of my tools so the mental overhead of doing that operation is low. An then if you want to transfer it into a SQS friendly format (one line all, quotes escaped), that operation is similar.
-
Walk these two DTOs and create a mapping function using name similarity. This kind of thing is harder to do cause determining similarity is hard, but it can save a lot of typing with simple mapping.
-
Take this JSON we designed for our API and generate all of the resources to create, delete and update it.
-
Take this GET endpoint reverse it and add a second endpoint that is the update version of it.
When you start operating over the code base instead of writing in the codebase, you start building a toolset that is hard to beat and easily composible.
A good place to start for Python is LibCST by Instagram. At work I have been using this to create AWS lambda workflows and more easily modify those workflows through this mapping and re-templating pattern. When you have more programtic access to your codebase it is much easier to write integration tests that automatically know the shape of your codebase, or expose common funcitons that you need to setup or test your infrastrucutre to developers directly. LibCST is helpful also because it preserves comments and whitespace so you dont get the large diffs that you might using Python’s built in AST.
For Java code I have not found a good AST to use but parsers are not very hard to write, especially if you use LLM tools to automatically write them, so at this point I have quite the library of parsing and re-writing tools, it does take a bit to set them up (on the order of a few days), an they are somewhat brittle to major refactors in your codebase, but if you rely heavily on the LSP for traversing the links between files, it can be quite robust. The Java Redhat LSP for VSCode does not have all of the functions supported compared to the JavaScript LSP, so there is some trial and error figuring out why some LSP endpoints return no values.
Other Paradigms
Annotations
I have seen a few overlapping systems that try to do similar things to what I am talking about, mainly annotations + wiring and aspect oriented programming, of the two I think annotations are the most useful and least bad but still can be abused pretty horribly. Most of the problem with annotations is again information hiding, when a Spring endpoint has 5 or 10 annotations on it, each with their own code that they are running, again in separate interface files and then separate implementation files, tracking what each of these do is chaotic. I do not know how to better solve this piece of it and at least you can go lookup the relevant information. Now that I’m thinking about it, the real problem with annotations at least in their implementation in VSCode is that scrolling over them tells you the documentation for the annotation rather than the source code and control clicking the annotation takes you to the annotations interface rather than its implementation. The hover text should instead show you what code is added by the annotation with what inputs we have (e.g. if we have an @Path(‘/endpoint’) decorator show me the implementation of that Path annotation )
{
this.path =
’/endpoint’;
}
The control click should take me directly to the implementation of the decorator. I understand why this is not the default behavior (what if the implementation cannot be found? Not all annotations have code effects e.g. @Override is largely for the compiler checking that you are actually overriding a super method, but does not change the code whatsoever). When your IDE extension becomes your ultimate programming tool that is easy to shape and bend to your needs, it is not hard to see how we might go about fixing this. I have also heard that NeoVim allows for more granular changes to how it works with this kind of thing in mind, so that might be a better IDE to use.
I have been recently using Python’s decorator pattern pretty effecitvely to build command line interfaces that are composable, but I think that they should be minimal in their foot print. The way I have been using them is as a marker for UV run scripts. UV is a Python package manager that also lets you write and execute code directly from the command line, but limits you to having no arguments for these funtion calls. I think this is a good limitation since you want the commands to be composable and have a low user overhead. So I have been using decorators to mark which of my functions need to be exposed as UV commands and which commands apply to just the current repository or have a virtual command that applies to all repositories. For example I may want to deploy localstack against all of the repositories in my project and in the correct order to ensures no bad links. Alternatively, I may already have all of the repos up in localstack and just want to redeploy the current one.
This has been pretty useful for exposing complicated operations to other teams that have little domain knowledge of how our team’s APIs work.
Overall annotations only somewhat hide information, but at least provide backlinks to where I can learn more about how my code is being modified, in a perfect world I rather have everything be explicitly written out, but this balloons the size of the code base and makes locality of behavior harder, so this is a compromise I’m willing to live with.
AOP
AspectJ
For the unfamiliar, Aspect Oriented Programming is the idea that you can treat the methods in your code base like a big list and wrap each method with logging and other changes to the code when they meet certain conditions, e.g. if some flag is set go to all methods that hit a remote endpoint and change that remote endpoint to local one, or for every method that is an implementation of a REST endpoint, create a log message describing when you enter and exit the REST endpoints implementations. The “Aspects” (little pieces of code attached to methods) are then “weaved in” at either compile time or runtime into the Java-bytecode of the program. This is not the only way I’ve seen Aspects done but for the AspectJ compiler, this is how it is done.
On the surface this seems pretty similar to what I’m advocating for, it treats the codebase as an object that can be operated over, making changes that are repeatable and scalable. The problem as with most schemes is in its actual implementation. The changes occurring in the bytecode instead of the actual code leads to deal breakers for me. The first is information hiding, obviously by its very nature you can only know that your code is affected by an Aspect by already knowing first what this obscure scheme is and second knowing where the Aspect is that is affecting your methods.
I’ve only been able to figure this out in one of two ways, first I notice some odd behavior with the code that doesn’t match the actual written code, maybe a method that calls an endpoint fails when all other calls don’t fail, or even hitting the endpoint from Postman does not fail. This kind of thing is very hard to debug cause of the large number of things that could be wrong (is an environment variable incorrectly set? Did I deploy this version of the code to my docker container? Is my proxy correctly set? Is the endpoint blocked by my VPN? etc.) and usually I find out that it was an Aspect making the change by randomly looking at some other part of the code base or asking a co-worker what’s going on.
If we think from the beginner’s mind this is pretty hard to debug for very little benefit (we maybe save a few lines of code cleaning up some logging, or repeated code) and whenever we get a new team member we have to explain to them about a system that inserts bytecode seemingly at random into the codebase. This is only made worse by the fact that we are changing the bytecode instead of the code, this means that if you step through one of these statements in a debugger say in Intellij or VSCode, it will literally show you nothing while the statements generated by the aspect are being run. To actually debug something like this you either have to do println debugging, guess and check debugging, or go into the .class files and step through the lines of code with pen and paper!
CDK Aspects
The other place I’ve seen AOP used is in AWS’s CDK library. The CDK allows for writing Java or Python code that writes a dynamic Cloudformation yaml at deploy time. This CloudFormation yaml tells AWS how to both pull down and instantiate your AWS infrastructure for a specific stack. Most of this code defines the parameters for what AWS calls Constructs, these are either the lowest level infrastructure blocks that AWS supports or collections and abstractions of those low level blocks (think Java code that defines lambdas, ec2 instances, policies, roles etc.). The library then exposes a concept of an Aspect that runs when the constructs are being converted to the CloudFormation spec and you can write arbitrary code to work on each construct and its children either modifying constructs, removing them, or otherwise doing any code generation task that you’d like to apply over all of the constructs. And since this runs with compiled Java code instead of weaved JVM bytecode it is much easier to debug. This seems like it solves most of the problems of AOP, so why do I still not like it?
Well two reasons: first, that pesky problem of locality, since there is no backlink from the code that it affects, we are hiding information that is important to the new programmer! How do I know that any aspect is affecting my constructs? The aspect code itself may be multiple file traversals away from where the construct is made and since AOP is not a common practice why would I suspect that an object created multiple folders away is affecting every object I make in my stack? Once you have dealt with these aspects a few times you learn to look out for them cause they are trouble makers. If I wrote the codebase this would be one thing, but I am often diving into legacy code that has had hundreds of people working on it, so these landmines are often tucked away into a corner until you spend a day’s time trying to figure out why the code you wrote is doing something other than what it says it’s doing.
Maybe this can be smoothed over with documentation in the top level README, but having a sign that says “warning there might be landmines in this field” is not as good as removing the landmines in the field or not placing them down to begin with.
Experiments with LLMs and Results
Role of AI in Code Generation
With the size of the internet there is effectively infinite specific knowledge that can be learned on human time scales. But fortunately, my buddy Chat-GPT has read the entire internet and only hallucinates documentation sometimes. I have found that LLMs are pretty useful in finding new ways to do things and summarizing tools I didn’t know about. They are also pretty good at generating code that follows publicly available documentation, so if you cannot find example code, for example for a piece of VSCode’s Extension API, you can get an example of how it should be used and go from there. Especially when you are dealing with a library that only documents their code with human readable text, instead with of examples, this is pretty powerful and gives you a starting point to understand what that documentation text might mean.
OpenCode, ClaudeCode
I have been experimenting with using locally run models on OpenCode, the open source version of ClaudeCode. This has been mostly a failure, I have recently purchased a GPU with 24GB of VRAM and all of the models I have tried, DeepSeek R1, Qwen, OpenAI’s new open-weight model, Llamma 3 fail in the same ways. They spend a lot of time trying to figure out what to do, their context lengths arn’t long enough to do the problems I ask of them, and even when they do come up with a correct plan, they don’t call the tools that they’d need to impliment it. The tools provided by OpenCode are things like Read from file, Write to file, List files in the directory. After trying all of the models that said they had tool use on them I could only get Qwen to even write to a file and it only did it once in about an hour of experimenting.
Cursor and Chat-GPT 5
So I paid for the pro plan of Cursor during the free period of Chat GPT 5-High and it is miles better than OpenCode at tool calling, but still fairly limited in its usefulness.
Experiment 1: CSS Cleanup
Rating: 7/10
I asked Cursor Agent mode plus Chat GPT 5 to go through the HuGo code that renders this website and cleanup any unused or auto-generated classes, remove the unused ones from the style.css main file and rename auto-generated class names to something human readable. I tend to take the CSS I like from around the Internet, so it has varying levels of readability and making sure that its something I can later edit is important.
It performed this task fairly well, but really only completed the task to rename/remove auto-generated tags and did not remove any unused but human-readable tags, even though I know they exist. In Chat GPT 5’s thinking it realized that the auto-generated tags were of the form css-Yh321J so it greped those tags and replaced them.
It makes sense that it could not figure out how to remove unused tags since it would probably need a HuGo LSP in order to figure this out. Or, it could have compiled all of the CSS classes in the style.css into a list and greped for occurrences of the classes outside of the file and removed those unused classes programatically.
First, it is kinda of incredible that I can tell it to go and clean up the CSS on this website and it does a reasonable job. For me to do the same job I’d have to go to each class, figure out where it is used and give it a name that may or may not correspond to its actual function.
The approach I should have taken was to have it write that programmatic approach in a VSCode extension, that way I can expose it to the AI in the future as an MCP server tool and also if I need to perform the same task again maybe as a build step before shipping the website, the code is easily callable. I think in general asking LLMs to do long range tasks that touch multiple parts of the code base is pretty tricky. As I have discussed above the same is true for humans and so we should aim to write shorter and reusable code snippets that are callable by script/keybinding/MCP.
Experiment 2: Blender Character Creator
Rating: 4/10
For a while now, I have wanted a “Human Generator” in Blender that acts like the Skyrim Character Creator. It would have some slider around the size and placement of different body parts and then outputs a 3D mesh with bones and weights. Then I could go in and refine the sculpture with Blender’s sculpting tools. Similar to Meta-Human but free and without the license problems. I thought that Blender’s Geometry Nodes system would be a good place to start since they allow you to programatically make meshes and animations.
After a lot of back and forth, I got the addon to compile and generate a mesh. The mesh has arms, legs, hands, a head, and a torso. The hands are not visible, the arms and legs are attached to the torso and are not mirrored about the head, etc.
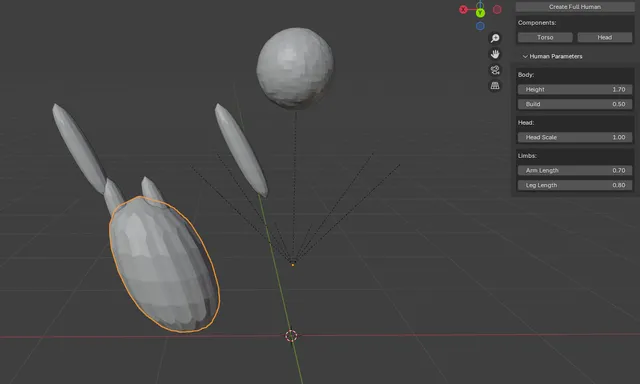
I asked the model to make fingers attached to the hands and make the hands visible, which it did and it gave the fingers armatures, but the fingers are inside of the hands now and much smaller than the hands.
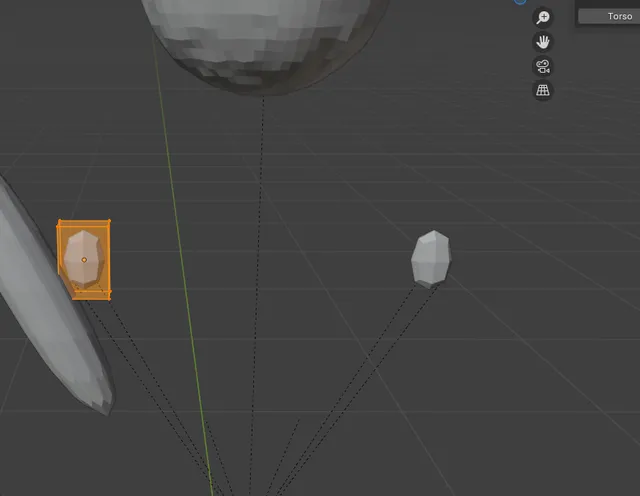
I think the next step will be to get an actual description of the bones in the body and their connections from the Internet and then have the model make a skeleton. I think in general the more tasks that you try to have the model do at once the worse it preforms. In the example above I actually asked the model to fix all of the thing wrong with the generated mesh giving it a list of tasks to complete. It correctly broke down the list into subtasks but only completed the one about fingers, and only half way. Is this a limitation of Cursor or of Chat GPT 5? Giving it a good plan of attack is as important as understanding what is in or out of scope of the training set for the model.
As a side-note I have often found after going to Google after a LLM fails to give me a satisfactory answer to a programming or documentation quesiton that I have, it is usually the case that the question I am asking has only a few answers across the web and you can see that the Lanugage Model has chosen one of them as the “correct answer” even though it does not work. Likely this is due to how the models are trained, weighting higher SEO websites better in their training set, though I dont have enough evidence for a root cause.
Experiment 3: Image Converter and Insertion
Rating: 6/10
I wanted to have a right-click utility in File Explorer that takes any image that I am clicking on, convert it to a WEBP no larger than the max render size on this website (600px maximum width or height), and then insert the image into my HuGo codebase. The first attempt I made at this, the model correctly made the registry edit changes to allow for the right click menu and the code to convert the image. I then had to figure out how to package the Python code it generated into an EXE for the right click to run.
Getting the model to write code is fine but getting it to think about the user pipeline is hard. Here are the questions I ask myself to understand if I have something reliable or not:
- Can I build and redeploy my code in one click or command?
- How many steps does it take to setup the developer environment after cloning the repo?
- Can I access all of the required user flows from the tool I am making?
If the answer to any of these is no, then we have some more work to do.
I next made the design error of asking the model to figure out how to add sub-menus to the right click tool. This was a mistake because it requires deep knowledge of the Windows Registry that the model likely doesn’t have. From what I understand the Windows Registry is pretty poorly documented and finicky, changing significantly on every Windows release. This is a poor environemnt for our LLM to work in. If you add the fact that the Registry doesn’t have any concept of a project or group of edits, then cleanup becomes pretty hard.
After wrestling with this for a while not getting the sub-menus to appear, I decided that a different approach was needed, an built more functionality into the terminal that pops up when the right click happens.

I used the sixel format to preview the image in terminal and the terminal to select where to send the image. There were the standard issues here of which image display library to use, how to install it, etc. and most of this was not solved by the model unfortunately. The next steps are probably to update the user prompt to choose which essay or card description markdown file to stick the image in and some way to quickly rename/re-caption the image.
Experiment 4: Porting to WebGL
Rating: 5/10
I have wanted to have my TSP code available to try out on my website without needing to download anything. Usually this is achieved through a game engine that cross compiles to WebGL for browser and OpenGL for desktop, think Unity’s cross platform support or libgdx. Often this comes with its own baggage that I want to avoid like required splash screens, licenses and abstractions that are harmful to performance and speed of iteration. More generally I think you should remove dependencies where ever you can, they are often costly in the long run especially if you are tightly integrated with them. I instructed Chat GPT 5 to migrate my current codebase for project Ixdar, which uses the LWJGL Java native bindings, toward a cross platform abstraction layer that uses TeaVM and WebGL for web and LWJGL for desktop. There was another option to use CheerJ for WebASM compilation but this is a paid service.
Overall this was somewhat successful with some pretty major issues in architecture, that I needed to fix. Mainly I have noticed that the agent mode sticks code in essentially random places. Between sessions this is harmful because in a new session it has forgotten where it stuck the code from the last one and has to re-write it in somecases. It also does not correctly import Java files from the codebase instead opting for fully qualified class names (e.g. java.util.ArrayList instead of ArrayList with an import at the top).
It also overrelies on what it calls fallback options, for example if I’m trying to import a texture via a JavaScript REST call, it will try to use Java’s native getResourceAsStream call as a fallback, even though it acknowledges in its thinking and comments that TeaVM does not support this and only has modest support for embedding resources in the generated JavaScript (basically this only works for text files and uses a pretty complicated system to do so). Proper error handling might be to generate a pink and black texture when the web texture cannot load like you see in a lot of Source games.
I have also noticed that the farther you can break down the problem, the better it will do at the task assigned to it. It is pretty easy to list too many things wrong with the code it wrote (say A,B,C) and then it constantly references those problems in its thinking even when working on another problem D. This in general makes the agent take much longer to complete a given task and should be avoided. Simply note down all of the issues in a separate file and then feed them in one at a time.
The main pain points were the following:
-
I needed to replace the Java native file system with some sort of string buffer.
- This is important for loading the .ix files as they contain the point information for a specific Traveling Salesman Problem as well as other information like geometry, wormholes and the solution circuit. Also all of the shader code is essentially text files that are compiled and read into the GPU, so these needed to use a dual file system as well.
-
I needed to replace all AWT Fonts and Geometry calls with our own font system.
- I chose do use the MSDF Texture Atlas generator since I already had shaders writen to render arbitrary Signed Distance Field textures.

-
I needed to re-write all of the shader code to be compliant with OpenGL Embedded Systems Version 300.
-
I needed to re-write the texture and shader loading code to allow for asynchronous calls to get resources, as on web the main thread cannot block on IO. This is a good practice for desktop as well, but not one you usually implement until you need to.
I setup the web launcher to show an orange triangle so that I’d know if WebGL was working at all and it took quite a while before that basic triangle showed up. Solving the immediate problems listed above wasn’t too hard for the model, though there were several times where I ethier had to do major (>50%) re-writes of the model’s output or other wise throw away the output entirely and start over with a new understanding of what pitfalls it will focus on. Trying to have the model re-write the code it submitted with the structural flaws in mind is quite difficult and can lead to reverse progress or cascading errors.
It honestly reminds me of writing essays for school in word where the program was so buggy that you had to save off copies every few minutes to ensure you didnt lose hours of progress. I guess that really brings home the point that you want well defined features tested, accepted and submitted to your git repo before moving on to the next issue.
Getting the transpiled JavaScript to run without error and properly compile was essentially all done by me, I didn’t write any of the TeaVM JS hooks, but I had to find and debug all null pointer errors that arose out of differences between web and desktop. Because the transpiled output is longer than the model’s context window, and it removes all symbol information in the process, the model was essentially useless for the debugging process and would routinely invent reason with very little evidence for why either the error was unavoidable or part of some random piece of code that it knew about instead of searching the stack trace for the actual location of the error. This again is one of those areas where there likely is not a lot of text on the Internet of how to properly debug a program.

For example the above picture is the splash screen for Ixdar. All of the textures are flipped about the y-axis because of differences in how the PNG format stores its pixels and how OpenGL renders textures. The model thought that the issue was in the transformation matrix of the texture shader, but this would make very little sense, since the shader code was shared between web and desktop and the desktop version did not have flipped textures, so the only place you should look is in the web platform specific code.
With a cursory look at the desktop texture loading code and the web texture loading code, I could see that on desktop we were flipping the textures correctly, but were not on web. Getting the model to fix this was very difficult, even though it is a simple change. I think if I had wiped its context window and told it the exact problem, it might have been easier.
Experiments Takeaways
I think if you have these kinds of coding assitants work on your codebase it should be in a limited fashion mostly to accelerate the development of the more deterministic techniques discussed above. In most cases the probabalistic nature of these models and their high context cost, means that you rather have them write code that operates over the codebase than actually trying to make changes over the entire codebase. They are incredibly skilled at semantic translation (or style transfer in the domain of images) and so they can easily write tools that walk a Abstract Syntax Tree or convert a JSON into a Java class and reverse that.
What I have found is that they are pretty good for writing tools, since you dont need your tooling to be as robust as your production code. If something breaks at that level I can usually immediately see whats wrong, because the functions are simple enough, usually stopping at string manipulation and walking the codebase.
Where they fail is usually in this higher level domain of “If I make change X here how does that effect feature Y in some other part of the codebase” I think this is mostly since they don’t load the entire codebase and all of the reasoning that went into it directly into the model, and given the pricing structure where OpenAI charges for more input tokens you are disincentivized as a developer to load in that context.
Also, even if you correctly describe the change that you want to make, each file that it attempts to make the change in, it effectively has to re-figure out how to make that change denovo. This leads to situations where it may solve the problem in one way in one file and then a completely different way in another. This compounds with the number of files you are asking the agent to touch. If we say that each file has some probability of the model correctly fixing the issue, then we can quickly get to low single digit chances of the entire fix being correct.
For example if we say that the model has an 80% chance of making the correct change in any one of 10 files, then when we compound that chance
(80% of individual fix being correct)^10 = 10% chance of entire fix being successful!
With each separate change this gets expontentially worse, so by the time we need to make changes across 20 files we should expect the fix to work 1.1% of the time!
This does not mean that the situation is hopeless, but that we should learn to use deterministic code generation in tandum with probabalistic code generation so that we can repeat successes easily.
Future Work
The AI Ticket Destroyer
I think that the current code assistants leave much to be desired since they are the equivalent of the Jiminey Cricket version of the subconsious, constantly talking and commenting and refusing to make deletions. What I believe that we need to have truely transformative coding assistants is to combine traditional code generation techniques and search algorithms with this new decision and reading machnine called the LLM.
Most software that makes money is written for the enterprise customer and they have traditionally not wanted to deal with the fact that programming is closer to art than engineering, and so have built management structures to turn the group of hackers into a “Feature Factory”, the idea being that if you get good enough at the management of software engineers you can turn building valuable software into a reliable process. I think so far this has mostly not worked out and poor management is why software projects take so long. If coding assistants remain in the same realm of non-reliable software engineering, they will miss the opportunity to realize that ideal of the Feature Factory (See also X The Everything CLI).
Here is a plan for how I think you could actually make coding assistants useful to the enterprise customer:
-
Develop a tool integrated with JIRA, Github/Bitbucket, and VSCode that has a database of code generation tools (think ASTs and String Manipulation rather than LLMs) that can operate over your organizations codebase.
- It should be integrated with the suite of Atlassian tools since Management level people use these tools in their daily lives and also have purchasing power.
-
Make an ELO system for the tools so that you can rank them and search over them (maybe based on number of lines changed in the final PR compared to the initial run)
-
If you have this big library of code generators you can sort them by the language they work on (Python, C, Java, etc.) or further the framework they work within (e.g AWS, Azure, Springboot, etc.) and some of these categories overlap, but how would you get even finer categories like:
- “I only use this code generator to leave comments on my code”
- “I only use this code generator to update my api across the front end and back end”
- “I only use this code generator to split a codebase into sub-folders after a certain size that is too big”.
- “I use this code generator to create an interface to support multiple platforms when I currently only support one” (see WebGL Conversion Experiment)
-
Use the semantic understanding ability of the LLMs to search and sort JIRA tickets into one of the above buckets of existing code generators or decide to make a new one if there is no situation that has yet been encountered that we have an existing generator for.
-
Use the diffs between the generators first attempt and the checked in code to have the LLM either improve the main generator or create edge-cases or optional follow on generators.
-
Maybe that bucket sematic information could be appended and averaged over all of the situations where the generator was used and accepted by the programmer, but that could still be fairly nebulous. Like could you use LLMs to make the summary tags that apply to the generator?
The company’s moat would be the large repository of code tools and the searchability of those tools. Usually at work when I’m thinking of writing a dev tool it often takes longer to go find the appropiate tool either internally or from the internet than it would be for me to write the tool myself. There is a lot of things to read in the world!